library(rio)
data=import("data/Data_ejemplo_comunica.xlsx")Clase teórica Semana 12
chi2cuadrado
names(data)[1] "N" "Nivel de procastinacion"
[3] "RedSocial" "Tiempo en redes sociales"
[5] "Le gusta Leer" "Numero de interacciones diarias"
[7] "Numero de Seguidores" tabla1=table(data$`Nivel de procastinacion`,data$RedSocial)
print(tabla1)
Instagram Tiktok Twitter
Alto 20 33 15
Bajo 20 15 30
Medio 22 20 25chisq.test(table(data$`Nivel de procastinacion`,data$RedSocial))$expected
Instagram Tiktok Twitter
Alto 21.08 23.12 23.80
Bajo 20.15 22.10 22.75
Medio 20.77 22.78 23.45chisq.test(tabla1)$expected
Instagram Tiktok Twitter
Alto 21.08 23.12 23.80
Bajo 20.15 22.10 22.75
Medio 20.77 22.78 23.45chisq.test(tabla1)
Pearson's Chi-squared test
data: tabla1
X-squared = 12.638, df = 4, p-value = 0.01319Hipotesis nula: No hay asociación entre el nivel de procastinacion y la red social más consumida. Dado que el p-valor es menor que 0.05, rechazo la Hipótesis nula.
En conclusión a un 95% de nivel de confianza,si está asociados el nivel de procastinación con la red social más consumida.
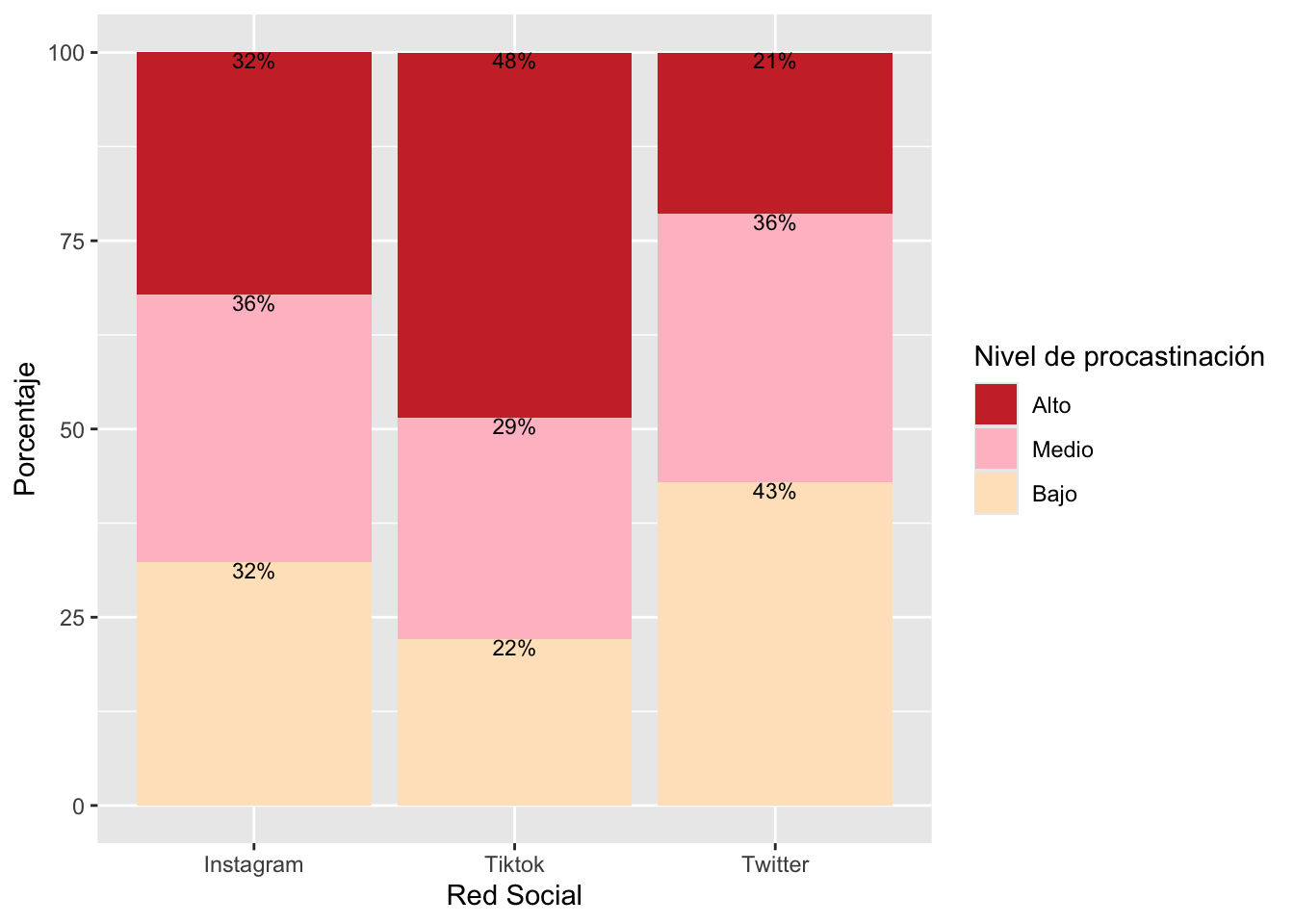
addmargins(prop.table(tabla1,2)*100)
Instagram Tiktok Twitter Sum
Alto 32.25806 48.52941 21.42857 102.21605
Bajo 32.25806 22.05882 42.85714 97.17403
Medio 35.48387 29.41176 35.71429 100.60992
Sum 100.00000 100.00000 100.00000 300.00000library(dplyr)tabla2 = tabla1 %>%
prop.table(2)%>%
round(3)*100
tabla2
Instagram Tiktok Twitter
Alto 32.3 48.5 21.4
Bajo 32.3 22.1 42.9
Medio 35.5 29.4 35.7tabla3=as.data.frame(tabla2)library(forcats)
tabla3$Var1 <- fct_relevel(tabla3$Var1, "Alto", "Medio", "Bajo")library(ggplot2)
ggplot(data=tabla3, aes(x=Var2,y=Freq,fill=Var1))+
geom_bar(position = "stack",stat = "identity")+
geom_text(aes(label=paste(round(Freq,0), "%", sep="")),
position = position_stack(), vjust=1, size = 3)+
labs(x="Red Social", y="Porcentaje", fill="Nivel de procastinación")+
scale_fill_manual(values = c("#CD3333","pink", "bisque"))